1. Introduction
Recent years have seen a wave of auto-research systems, including Auto Research [1], AI Scientist [2], and Analemma's FARS [3]. These projects have shown impressive progress in automated end-to-end scientific research. Rather than proposing another complex framework, we study a more direct setting: whether widely used general-purpose CLI agents (e.g., Claude Code, Codex, Kimi Code) can carry out research with only minimal guidance. Moreover, there is no comprehensive evaluation of the quality of agent-conducted research across diverse domains or under varying computational constraints (e.g., CPU-only vs. GPU environments), making it difficult to systematically assess the true capabilities and limitations of such agents in realistic research scenarios.
We evaluate three off-the-shelf CLI agents — Claude Code with Opus 4.6 [4, 5], Codex with GPT-5.4 [6, 7], and Kimi Code with K2.5 [8, 9] — using a minimal scaffold on 13 diverse CS domains (5 CPU-only + 8 GPU environments). We employ a peer-review protocol where three CLI agents evaluate each paper alongside its code, and additionally use the Stanford Agentic Reviewer [10] for external validation.
Key Findings
Each CLI agent develops a distinct research persona: Claude Code is the full-stack researcher — balancing both strategies (46% empirical, 33% novel methods) with the longest, most comprehensive papers. Codex is the empirical scientist — 87% empirical studies, highest integrity, but lower novelty. Kimi Code is the system builder — 79% of its papers are framed as novel methods with acronym-heavy names, yet it still scores low on novelty because many of its ideas sound more like repackaged existing work than genuinely new contributions.
Stanford Agentic Review (SAR) (0–10, ICLR scale):
- Among automatic systems: Claude Code (5.45) > FARS (5.06) > Codex (4.93) > Kimi Code (4.24). Our minimal scaffold with Claude Code (5.45) surpasses Analemma's FARS (5.06) using only a $200 Max subscription, compared to Analemma's $186,000 budget.
- Compared to 200 human-authored ICLR 2025 papers, Claude Code (5.45) scores above the weighted average of human-authored submissions based on the acceptance rate (5.42), sitting between accepted papers (5.59) and rejected papers (5.34).
- But human-annotated accept rates reveal a wide gap: ICLR Accepted 76.0%, Claude Code 41.0%, FARS 21.6%, Codex 12.8%, Kimi Code 5.1%.
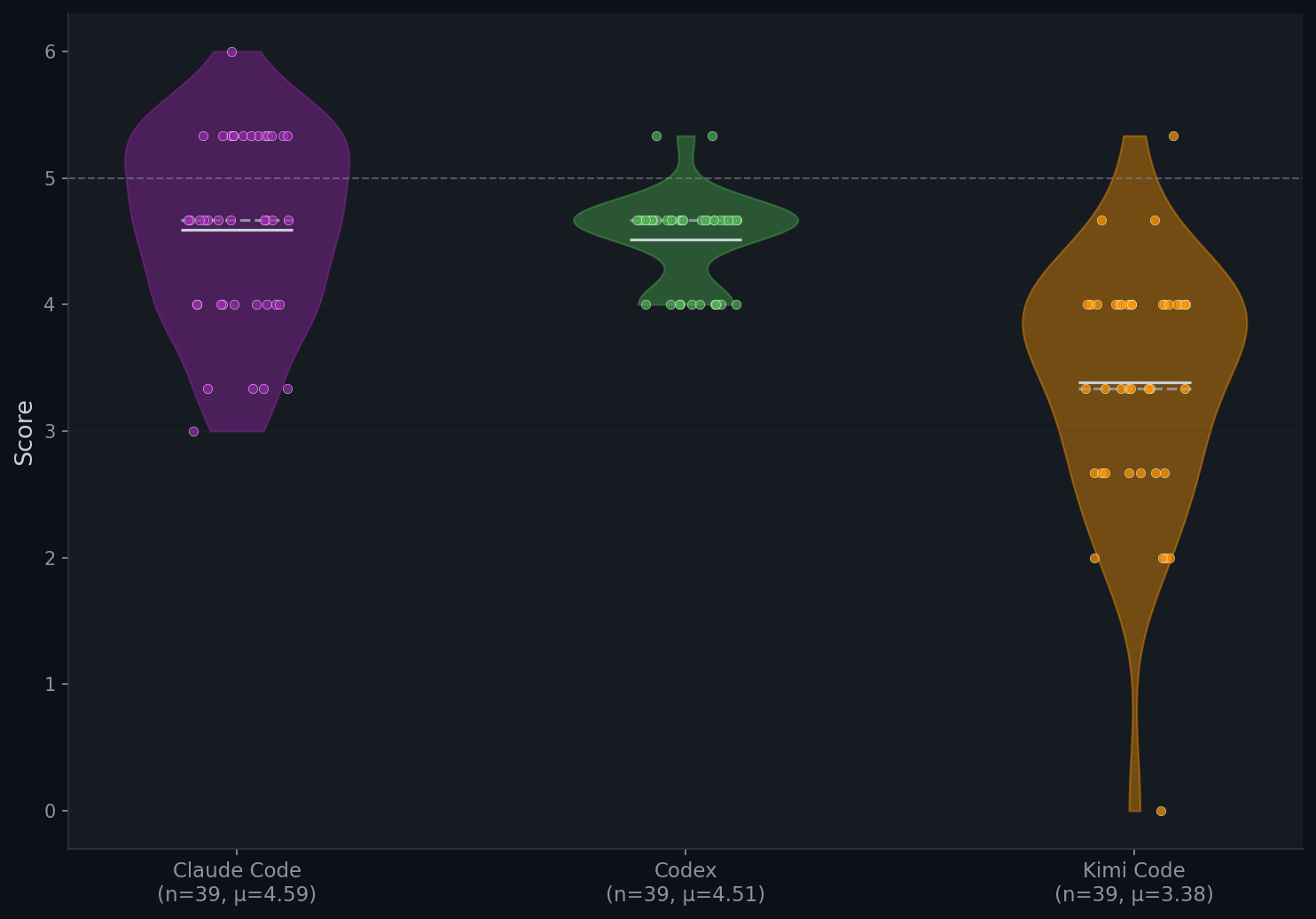
Peer Review (PR) (0–10, ICLR scale):
- Claude Code (4.59) > Codex (4.51) > Kimi Code (3.38). Our PR is stricter than SAR because it gives the reviewer access to experiment code and execution logs, enabling systematic checks for fabricated or unsupported results. This may sometimes be overlooked even by the human expert.
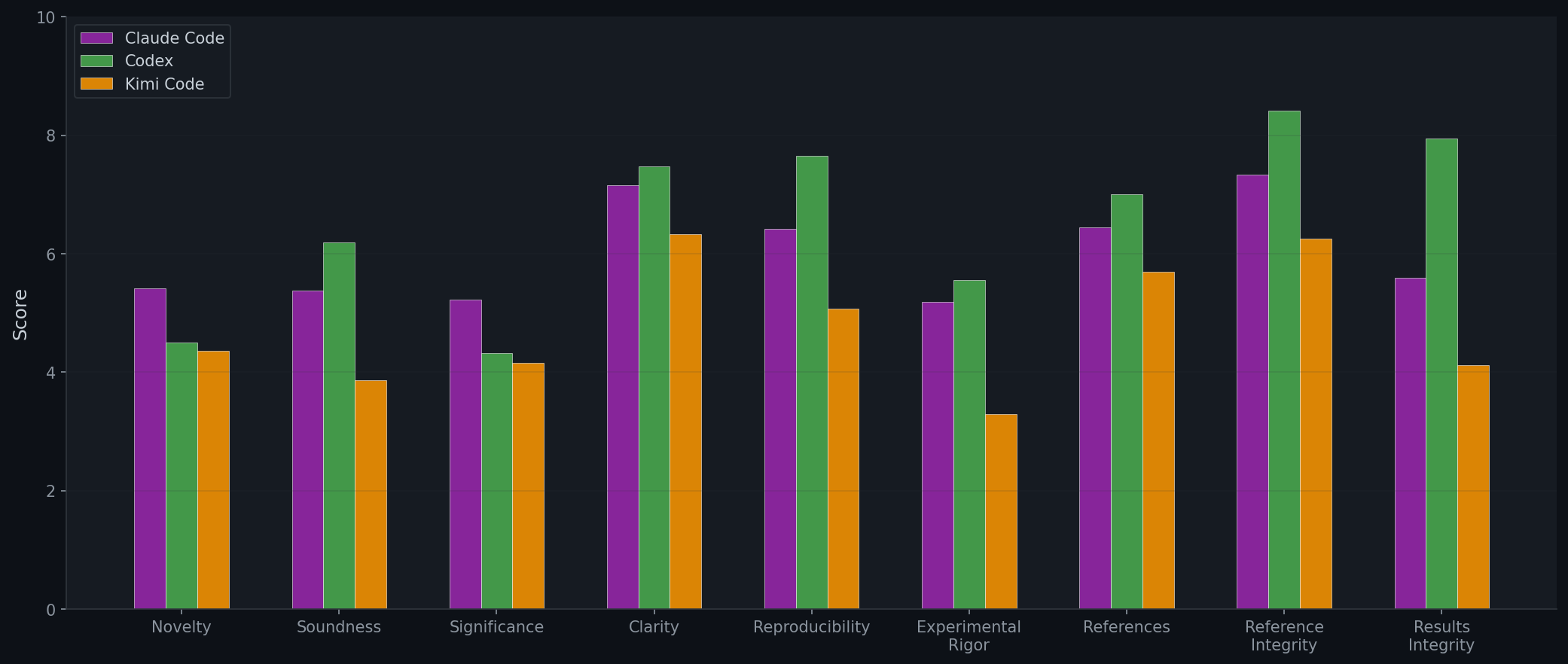
- The major weakness for CLI agents are experimental rigor and significance. Agents perform relatively well on reference integrity (Codex: 8.41/10) and clarity (Codex: 7.47/10).
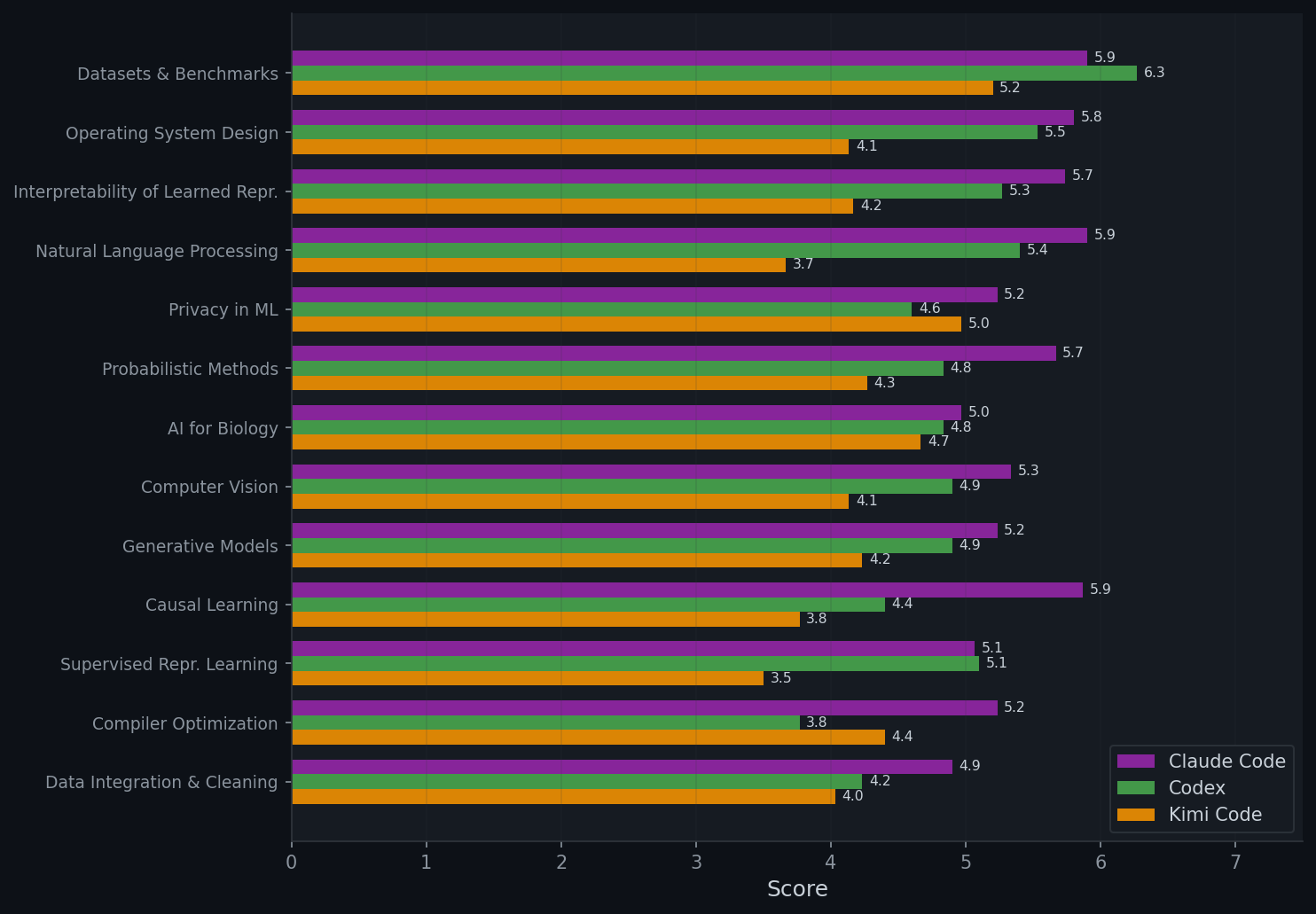
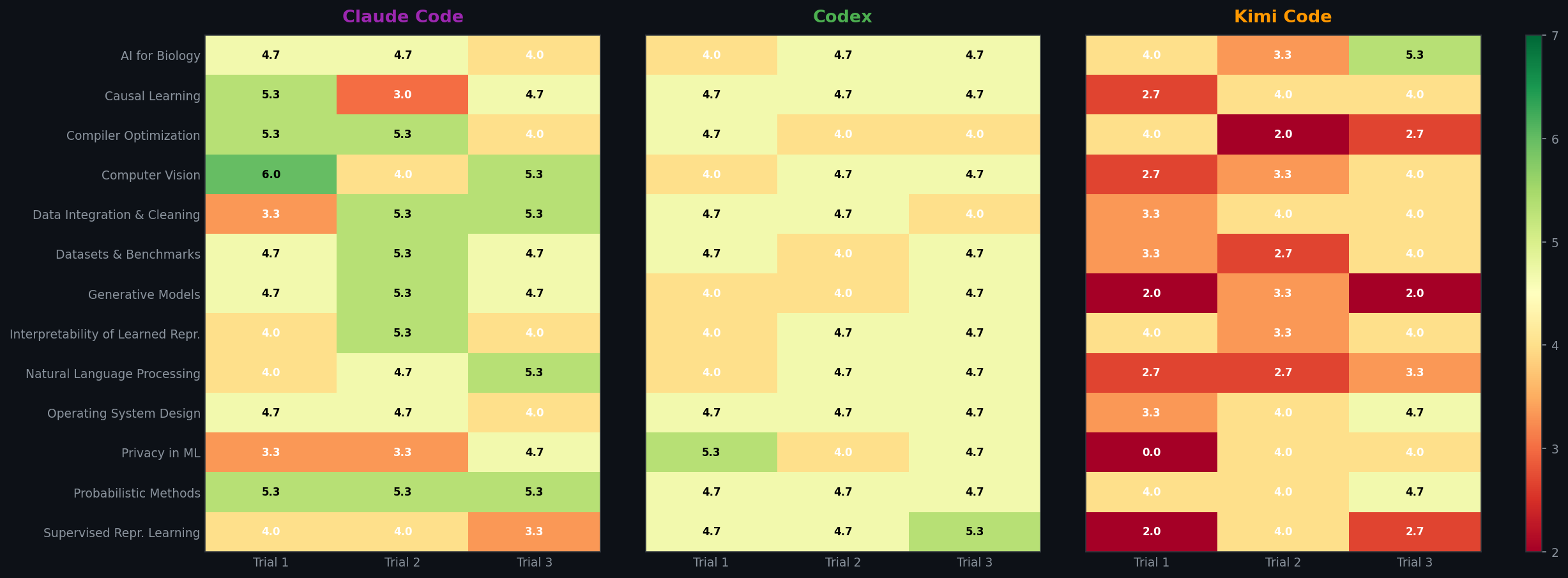
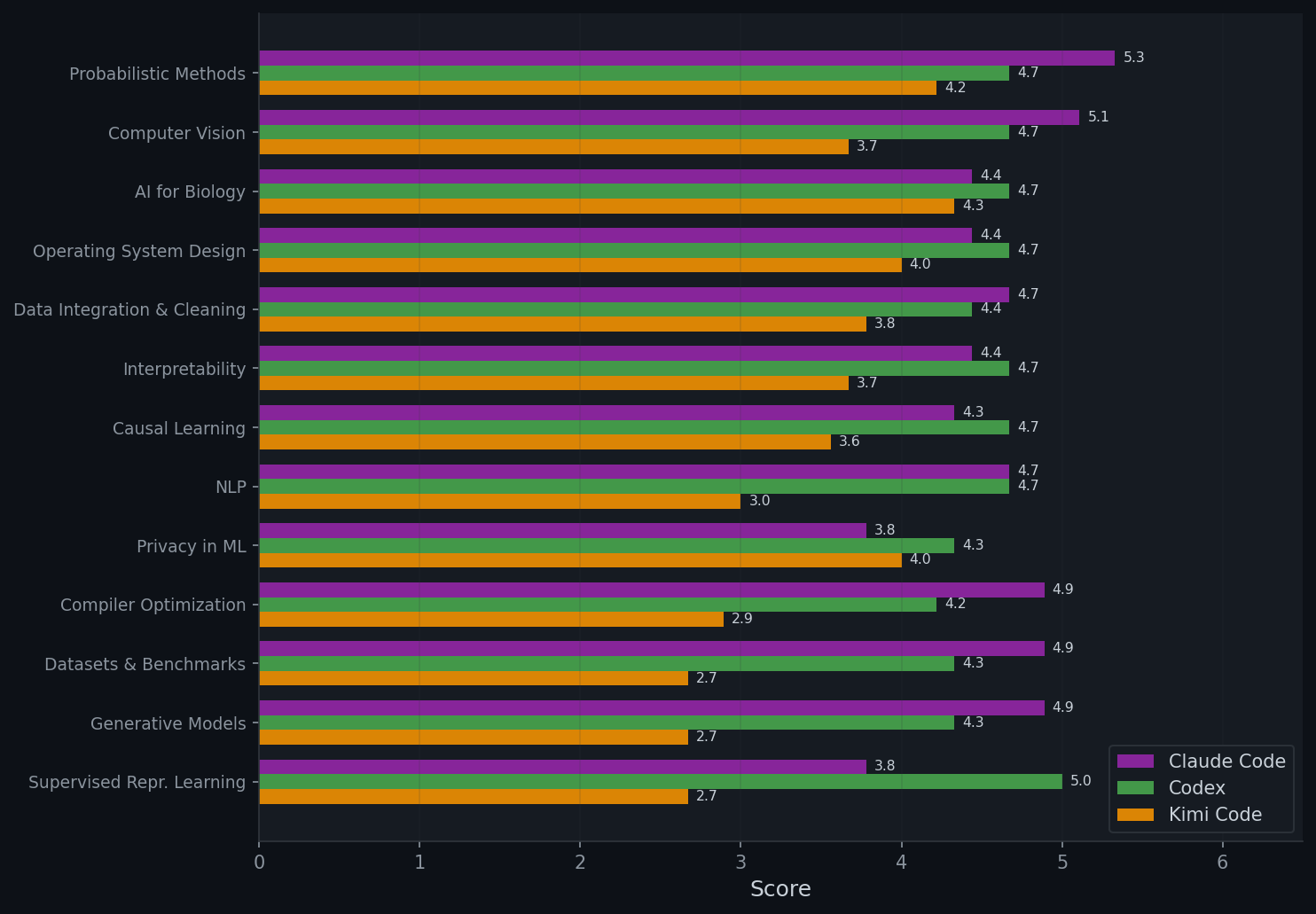
- Performance varies substantially across domains — Claude Code ranges from 5.33 (Probabilistic Methods) to 3.78 (Privacy in ML). Using stronger GPUs (RTX A6000→H100) shows no overall improvement, and in some cases even leads to lower scores, which further validates the major weaknesses.
- Manual integrity checks reveal sharp divergence between agents: Kimi Code has both results + setting mismatches in 77% of papers and fake references in 72%; Codex is the most trustworthy (5% / 8%); Claude Code sits in between (31% / 36%).
Human Inspection :
2. Framework Overview
Each CLI agent follows a standardized pipeline:
- Ideation — Generate a research idea and experiment plan; self-review for up to 3 iterations.
- Experiments — Write and execute code, collect results; self-review for up to 3 iterations.
- Paper Writing — Produce a paper; self-review for up to 3 iterations.
- Review — Evaluate via Stanford Agentic Reviewer and triple peer review (all three agents review each paper alongside its code).
3. Experiment Setup
| Agent | Model | CPU Seeds | GPU Seeds | Trials/Seed | Total Papers |
|---|---|---|---|---|---|
| Claude Code | Opus 4.6 | 5 | 8 | 3 | 39 |
| Codex | GPT 5.4 | 5 | 8 | 3 | 39 |
| Kimi Code | K 2.5 | 5 | 8 | 3 | 39 |
CPU seeds: Causal Learning, Compiler Optimization, Data Integration & Cleaning, Operating System Design, Probabilistic Methods
GPU seeds: AI for Biology, Computer Vision, Datasets & Benchmarks, Generative Models, Interpretability, NLP, Privacy in ML, Supervised Representation Learning
Hardware: CPU-only or 1× NVIDIA RTX A6000 (48GB). Each agent gets 4 CPUs, 60GB RAM. We also conduct experiments for GPU experiments using NVIDIA H100 (80GB) GPUs.
Peer review (PR): Every paper is reviewed by all three agents (Claude Code, Codex, Kimi Code), scoring on 9 dimensions (novelty, soundness, significance, clarity, reproducibility, experimental rigor, references, reference integrity, results integrity) on a 0–10 ICLR scale.
Stanford Agentic review (SAR): Every paper is reviewed by Stanford Agentic Reviewer, which provides ICLR-calibrated scores on a 0–10 scale.
4. Main Results on Stanford Agentic Review
Automated Research Systems Comparison
We evaluate the performance of three CLI agents on the Stanford Agentic Reviewer (SAR). For comparison, we also collect scores from Analemma's FARS, which reports SAR scores for a total of 102 papers.
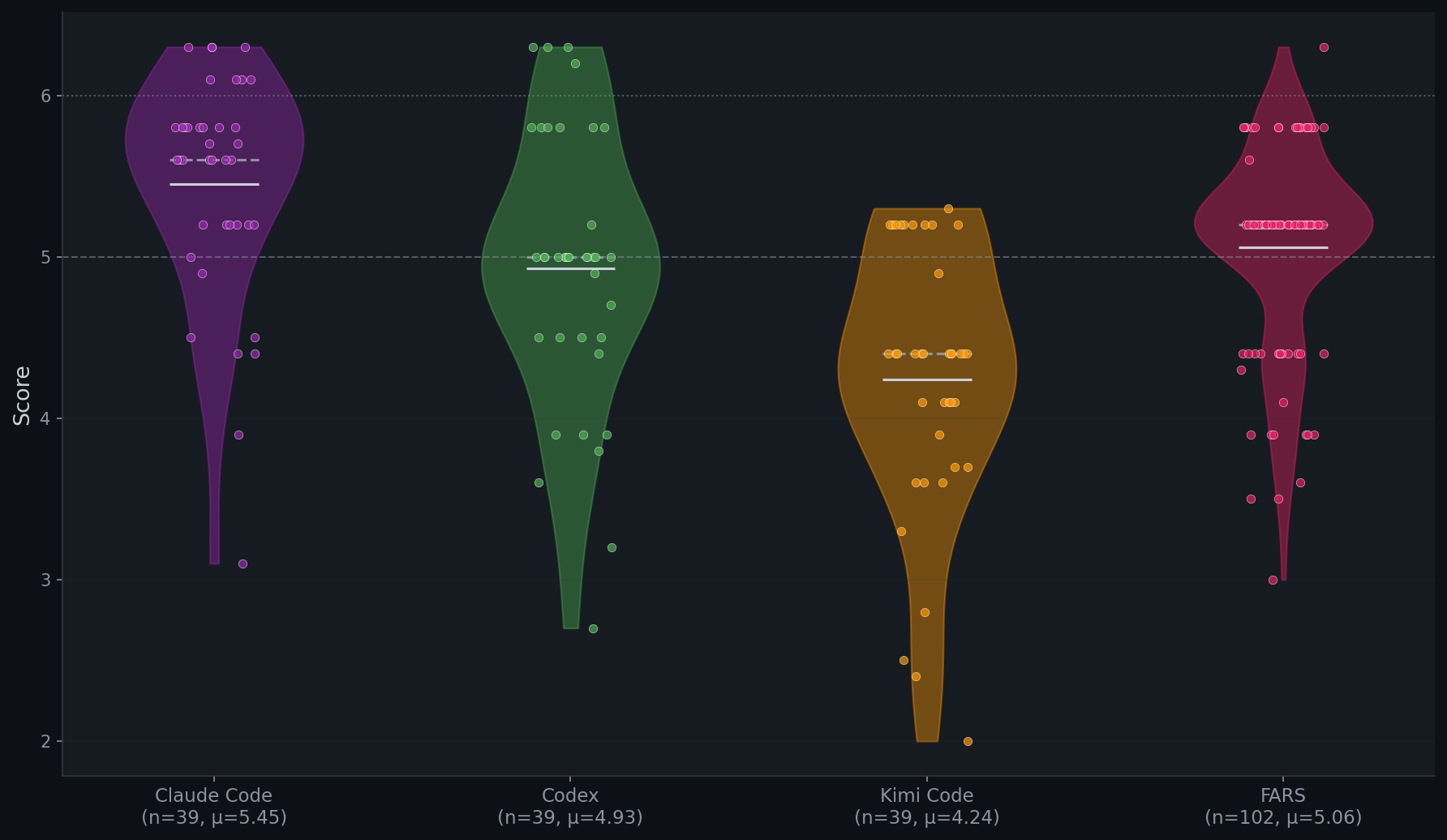
| System | n | SAR μ | SAR σ | Min | Max | ≥5.0 |
|---|---|---|---|---|---|---|
| Claude Code | 39 | 5.45 | 0.70 | 3.1 | 6.3 | 82% |
| FARS | 102 | 5.06 | 0.62 | 3.0 | 6.3 | 76% |
| Codex | 39 | 4.93 | 0.85 | 2.7 | 6.3 | 64% |
| Kimi Code | 39 | 4.24 | 0.84 | 2.0 | 5.3 | 26% |
Comparison with Human-Authored ICLR 2025 Papers
To calibrate these scores against human-authored research, we additionally sampled 200 real ICLR 2025 papers (100 accepted, 100 rejected) to the same Stanford Agentic Reviewer, establishing a human baseline.
| System | n | SAR μ | SAR σ | Human μ | Human σ |
|---|---|---|---|---|---|
| ICLR 2025 Accepted | 100 | 5.59 | 0.59 | 6.54 | 0.80 |
| Claude Code | 39 | 5.45 | 0.70 | — | — |
| ICLR 2025 Weighted (32%/68%) | 200 | 5.42 | 0.70 | 5.50 | 0.81 |
| ICLR 2025 Rejected | 100 | 5.34 | 0.75 | 5.02 | 0.81 |
SAR = Stanford Agentic Reviewer score. Human = average OpenReview score from ICLR 2025 human reviewers.
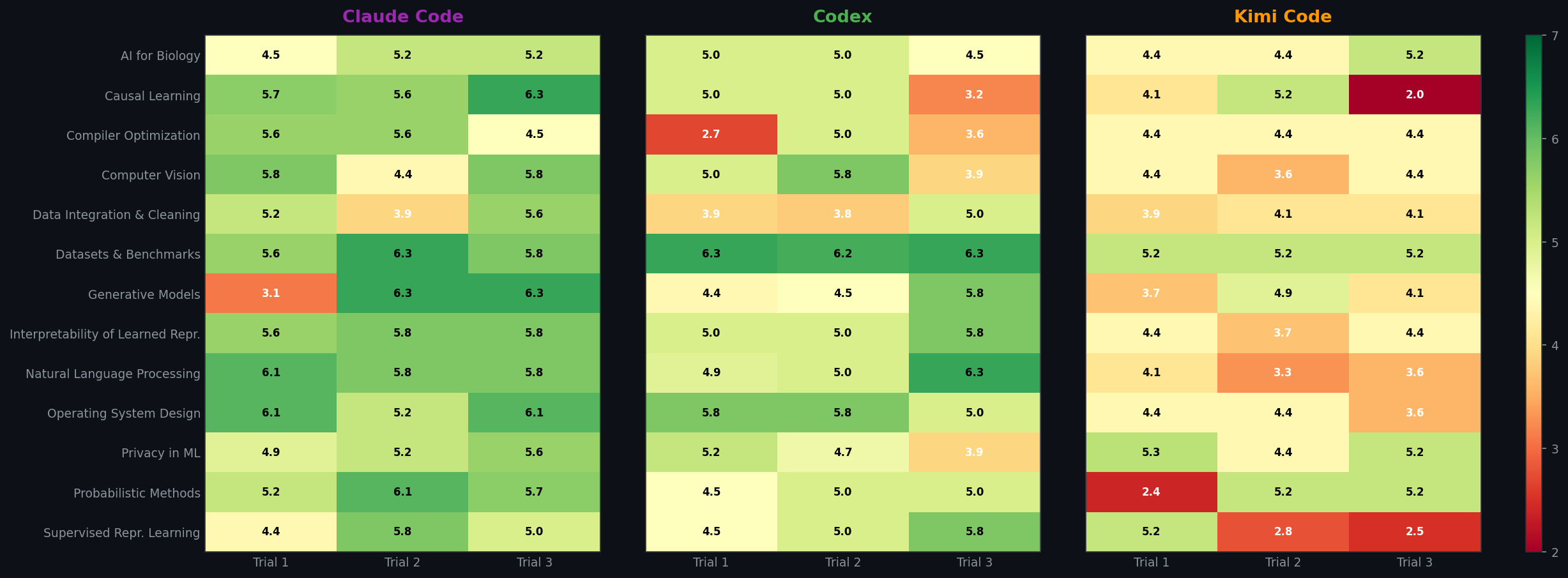
Score Heatmap (Seed × Trial)
Per-Domain Breakdown
We break down SAR scores across 13 research domains (5 CPU-only, 8 GPU) and compare CPU vs GPU performance for each agent.
CPU vs GPU Performance (SAR)
| Agent | CPU | GPU | Gap |
|---|---|---|---|
| Claude Code | 5.49 | 5.42 | +0.07 |
| Codex | 4.55 | 5.16 | −0.61 |
| Kimi Code | 4.12 | 4.32 | −0.20 |
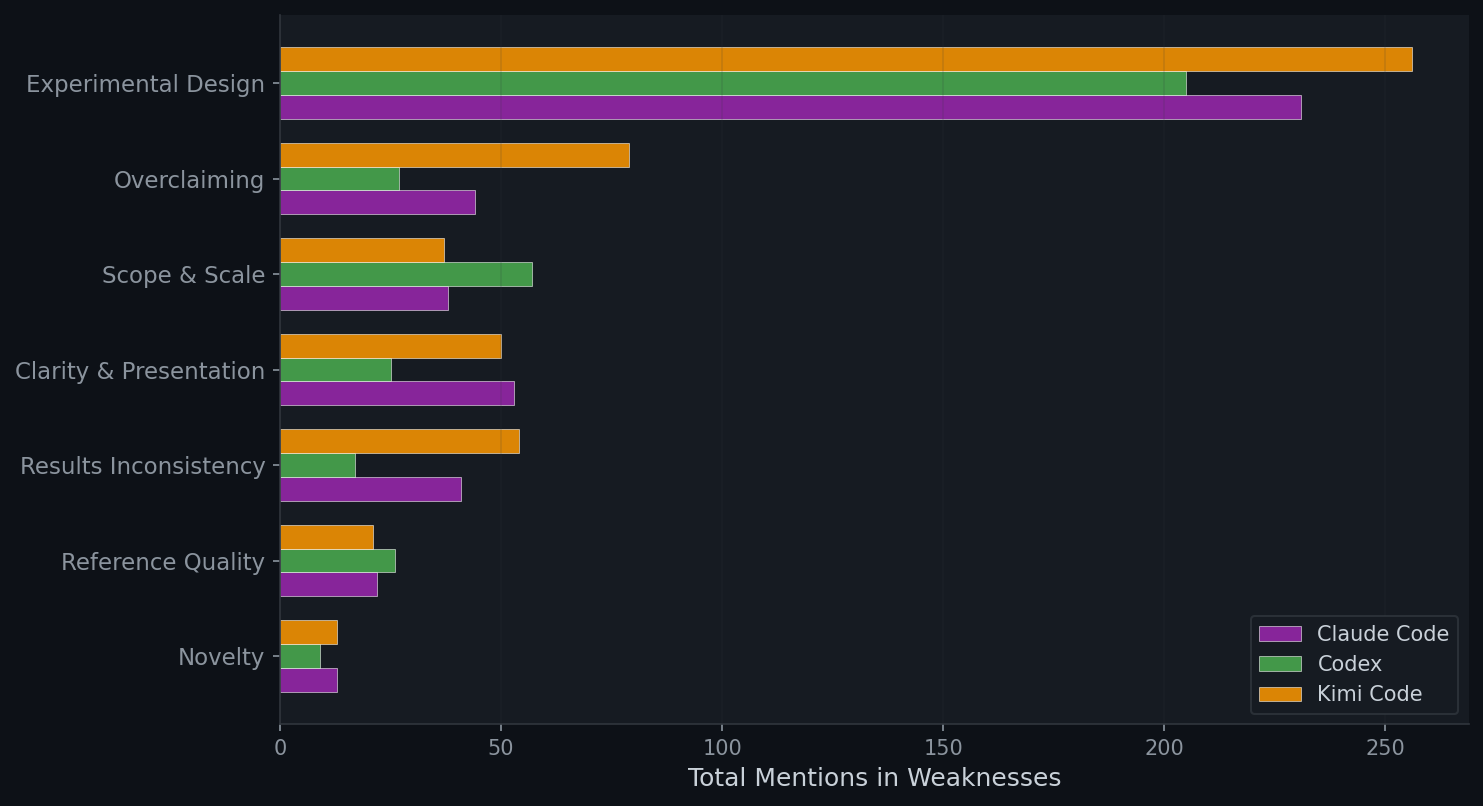
Qualitative Review Analysis
We analyze the text of Stanford reviews to identify common weakness themes via keyword matching across 7 categories: Experimental Design (baselines, ablations, evaluation, statistical rigor), Overclaiming (unsupported or exaggerated claims), Scope & Scale (limited or toy experiments), Clarity & Presentation (unclear writing, confusing notation), Results Inconsistency (contradictions or mismatches within the paper), Reference Quality (fake citations, placeholder references, future dates), and Novelty (incremental or trivial contributions). We also measure the balance between strengths and weaknesses across agents.
| Agent | Avg Strengths (words) | Avg Weaknesses (words) | Ratio (W/S) |
|---|---|---|---|
| Claude Code | 215 | 316 | 1.47 |
| Codex | 212 | 276 | 1.30 |
| Kimi Code | 184 | 339 | 1.85 |
Human-Annotated SAR Decisions
We manually inspected all papers together with their SAR reviews and found that the overall assessment score is not a reliable indicator of SAR's final recommendation. For example, some papers with scores above 6 were not recommended for acceptance, while others with scores around 4.5 were recommended for acceptance. Due to this inconsistency, we manually assigned accept or reject labels based on SAR's final recommendation rather than its numeric score. In some cases, the review does not explicitly state an accept or reject decision; in those instances, we inferred the recommendation from the overall tone of the review, judging whether it was more "accepted" or more "rejected". Moreover, we treat conditional accept, accept with revision, and borderline (accept) as accept decisions; all others are treated as rejection.
| Category | Accept | Reject | Accept % | Accept/Reject |
|---|---|---|---|---|
| ICLR 2025 Accepted | 76 | 24 | 76.0% | 3.17 |
| ICLR 2025 Weighted (32%/68%) | 59.7 | 40.3 | 59.7% | 1.48 |
| ICLR 2025 Rejected | 52 | 48 | 52.0% | 1.08 |
| Claude Code | 16 | 23 | 41.0% | 0.70 |
| FARS (Analemma) | 22 | 80 | 21.6% | 0.28 |
| Codex | 5 | 34 | 12.8% | 0.15 |
| Kimi Code | 2 | 37 | 5.1% | 0.05 |
5. Main Results on Peer Review
We design a peer review (PR) protocol where each of the three CLI agents reviews every paper alongside its experiment code, execution logs, and results artifacts. Unlike SAR, which evaluates only the PDF, this enables reviewers to verify whether reported results match actual experimental outputs, detect incomplete experiments, and identify fabricated claims. Additionally, reviewers are required to check reference validity via tools, flagging hallucinated or nonexistent citations.
Score Heatmap (Seed × Trial)
Per-Domain Breakdown
CPU vs GPU Performance
| Peer Review (PR) | Stanford (SAR) | |||||
|---|---|---|---|---|---|---|
| Agent | CPU | GPU | Gap | CPU | GPU | Gap |
| Claude Code | 4.73±0.20 | 4.50±0.10 | +0.23 | 5.49±0.16 | 5.42±0.15 | +0.07 |
| Codex | 4.53±0.07 | 4.50±0.05 | +0.03 | 4.55±0.23 | 5.16±0.15 | −0.61 |
| Kimi Code | 3.69±0.22 | 3.19±0.18 | +0.50 | 4.12±0.23 | 4.32±0.16 | −0.20 |
Per-Dimension Review Breakdown
Integrity & Reference Analysis
We further manually validate every paper with its artifacts and PRs across four integrity categories:
- Results mismatch only: numbers reported in the paper don't match the actual
results.json, logs, or experiment outputs. - Setting mismatch only: the paper claims to do things the code doesn't actually do: claimed components or ablations are never implemented, hyperparameters in the text differ from the config, or the method is not implemented as described.
- Both: papers flagged for both results and setting mismatches.
- Fake reference: citations that don't exist, have fabricated authors, or have incorrect bibliographic metadata.
| Category | Claude Code | Codex | Kimi Code |
|---|---|---|---|
| Results mismatch only | 6/39 (15%) | 2/39 (5%) | 4/39 (10%) |
| Setting mismatch only | 10/39 (26%) | 1/39 (3%) | 5/39 (13%) |
| Both (results + setting) | 12/39 (31%) | 2/39 (5%) | 30/39 (77%) |
| Fake reference | 14/39 (36%) | 3/39 (8%) | 28/39 (72%) |
| Mean refs per paper | 15.1 | 12.8 | 10.5 |
| Reference integrity score | 7.34 | 8.41 | 6.26 |
Programming Language Usage
We analyze the programming languages and file counts across all agent-generated codebases to understand how each agent structures its experiments.
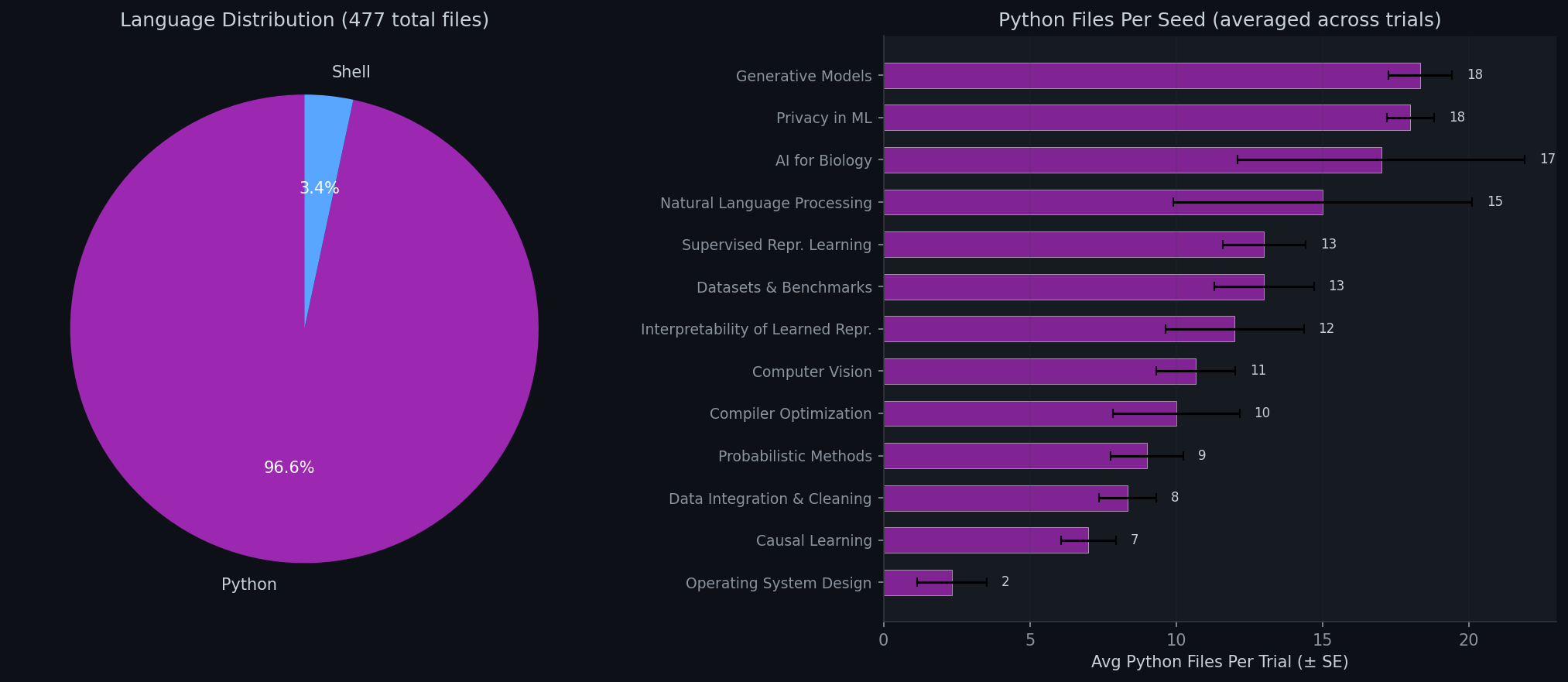
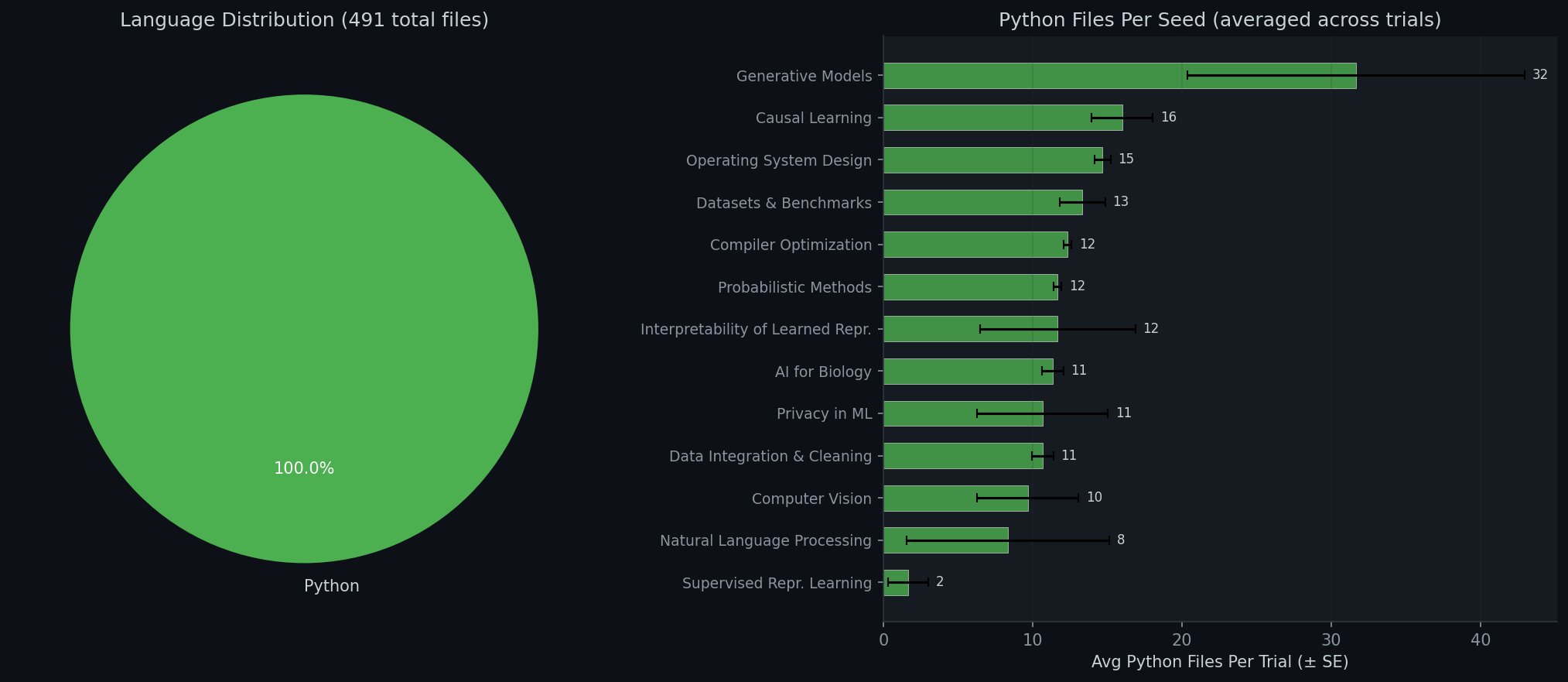
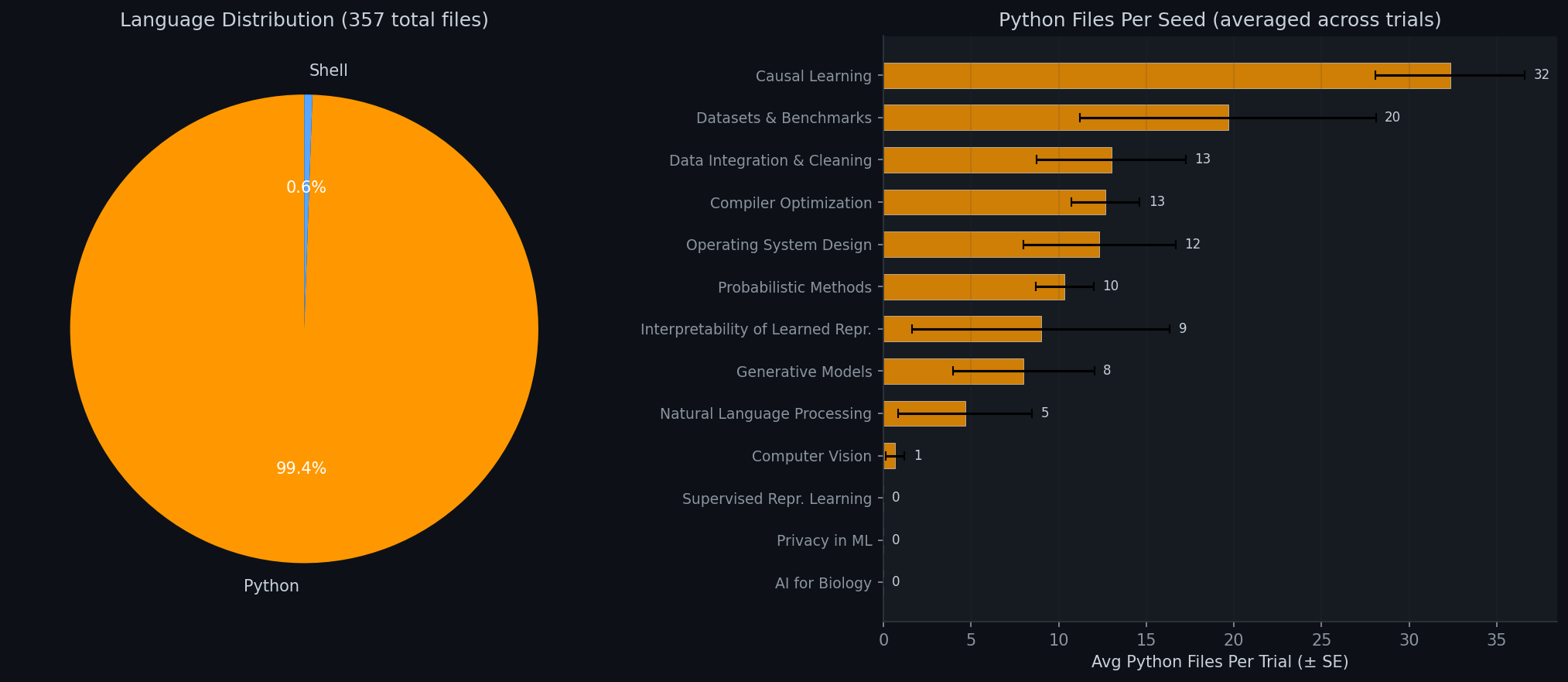
6. Research Style Analysis
Beyond scores, we compare how each CLI agent approaches research — what types of papers they write, how they structure arguments, and what their titles reveal about underlying research strategy. This comparative analysis shows that the three agents have developed fundamentally different research personas, which in turn explain many of the quality differences observed in Sections 4–5.
Research Type Distribution
We manually classify each paper based on its title and abstract into three categories: novel method (proposes a new named algorithm or system, including extensions or improvements to existing methods), new benchmark (creates evaluation tools), and empirical study (studies without proposing new methods).
| Type | Claude Code | Codex | Kimi Code |
|---|---|---|---|
| Novel method (incl. extensions) | 18 (46%) | 5 (13%) | 31 (79%) |
| New benchmark | 3 (8%) | 0 (0%) | 4 (10%) |
| Empirical study | 18 (46%) | 34 (87%) | 4 (10%) |
Title Structure Analysis
| Metric | Claude Code | Codex | Kimi Code |
|---|---|---|---|
| Avg title length | 102 chars | 99 chars | 92 chars |
| Question titles | 10% | 28% | 0% |
| Colon structure (Name: Subtitle) | 74% | 46% | 85% |
| Contains acronym (2+ caps) | 15% | 49% | 51% |
| Named method (starts with name) | 21% | 38% | 46% |
Title Vocabulary
The most frequent words in each agent's titles reveal distinct research personas:
| Agent | Top Keywords | Personality |
|---|---|---|
| Claude Code | learning when causal adaptive pipelines contrastive |
Full-stack researcher — spreads across research types |
| Codex | study benchmark negative matched controlled pilot |
Empirical scientist — controlled studies |
| Kimi Code | adaptive aware guided dynamic gradient contrastive |
System builder — named frameworks |
Title Patterns
Each agent has a distinct title style:
| Agent | Style | Example Titles |
|---|---|---|
| Codex | Question-based, hypothesis-testing. 28% use question marks — highest of any agent. |
"Do Shared Decoders Improve Prototype-Edit Reusability?" "When Does Clarification Supervision Transfer to Formal Reasoning?" "How Much Signal Is in Early Training Trajectories?" |
| Claude Code | Descriptive analysis. Unique "The X of Y" essayistic framing. |
"The Algebra of Compiler Passes: An Empirical Study of Idempotency" "The Bandwidth Knapsack: Optimal Migration Scheduling" "The Functional Anatomy of Sparse Features in Language Models" |
| Kimi Code | Acronym-heavy named frameworks. Zero question titles — always declarative. |
"CAGER: Causal Geometric Explanation Recovery" "DU-VPT: Decomposed Uncertainty-Guided Visual Prompt Tuning" "VAST: Velocity-Adaptive Spatially-varying Timesteps" |
Paper Structure
How do the papers differ in structure and technical depth?
| Metric | Claude Code | Codex | Kimi Code |
|---|---|---|---|
| Paper length (words) | 4,023 | 3,421 | 2,461 |
| Method section (words) | 572 | 531 | 394 |
| Equations | 3.8 | 2.3 | 4.0 |
| Figures | 4.8 | 4.1 | 0.8 |
| Tables | 6.0 | 4.2 | 4.0 |
| Algorithm blocks | 0.6 | 0.0 | 0.6 |
| Theorems / proofs | 0.3 | 0.0 | 0.4 |
| Complexity analysis | 77% | 10% | 64% |
All 39 papers per agent analyzed (117 total).
7. Reviewer Analysis
Our pipeline uses two layers of review. First, each agent self-reviews its own work at every stage (ideation, experiments, paper writing) for up to 3 revision rounds. Second, all three agents cross-review every paper in a peer-review setup. Below we examine whether self-review revision actually improves quality, and how much bias the peer reviewers introduce.
Self-Review Revision Effectiveness
When an agent scores below the self-review threshold, it revises and re-evaluates. The table below tracks whether scores improve, stay the same, or decline after revision.
| Agent / Gate | Improved | Same | Declined | Avg Delta |
|---|---|---|---|---|
| Claude Code / Idea | 100% | 0% | 0% | +2.1 |
| Claude Code / Experiment | 88% | 8% | 4% | +2.2 |
| Claude Code / Paper | 43% | 34% | 23% | +0.0 |
| Codex / Idea | 35% | 51% | 15% | +0.4 |
| Codex / Experiment | 78% | 20% | 2% | +2.0 |
| Codex / Paper | 64% | 29% | 7% | +1.5 |
| Kimi Code / Idea | 100% | 0% | 0% | +3.0 |
| Kimi Code / Experiment | 91% | 9% | 0% | +2.2 |
| Kimi Code / Paper | 61% | 34% | 5% | +1.6 |
Peer Review Bias
Each paper is reviewed by all three agents. The score distributions reveal large systematic differences between reviewers.
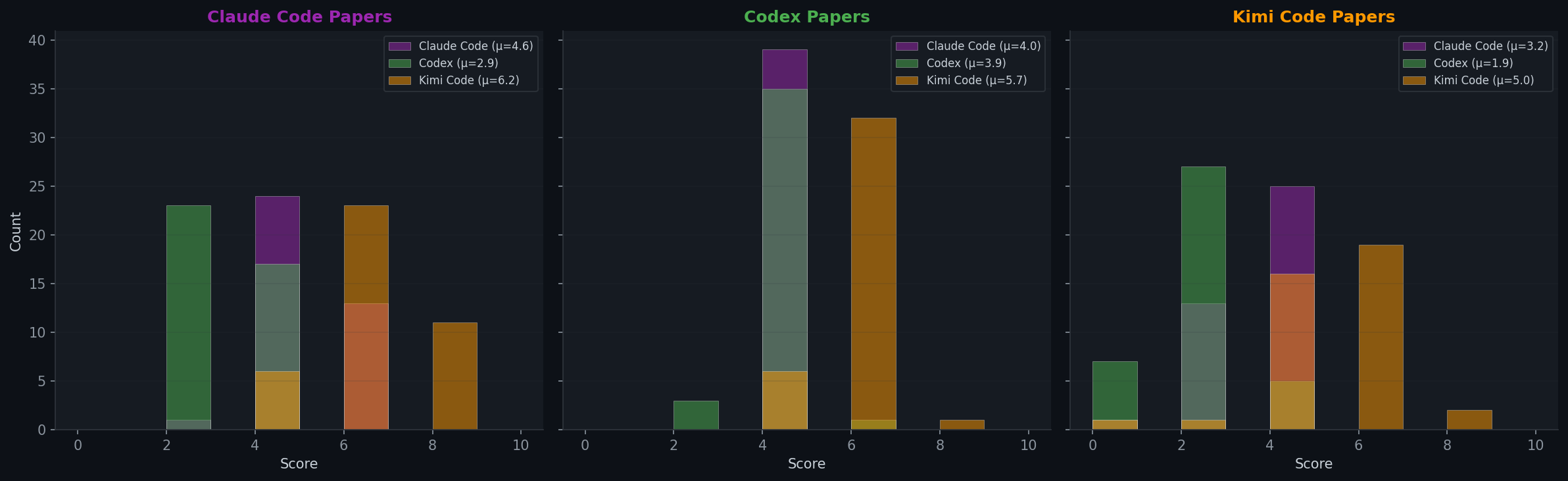
| Reviewer ↓ / Agent → | Claude Code | Codex | Kimi Code | Avg Given |
|---|---|---|---|---|
| Claude Code | 4.6 | 4.0 | 3.2 | 3.9 |
| Codex | 2.9 | 3.9 | 1.9 | 2.9 |
| Kimi Code | 6.2 | 5.7 | 5.0 | 5.7 |
8. Time Analysis
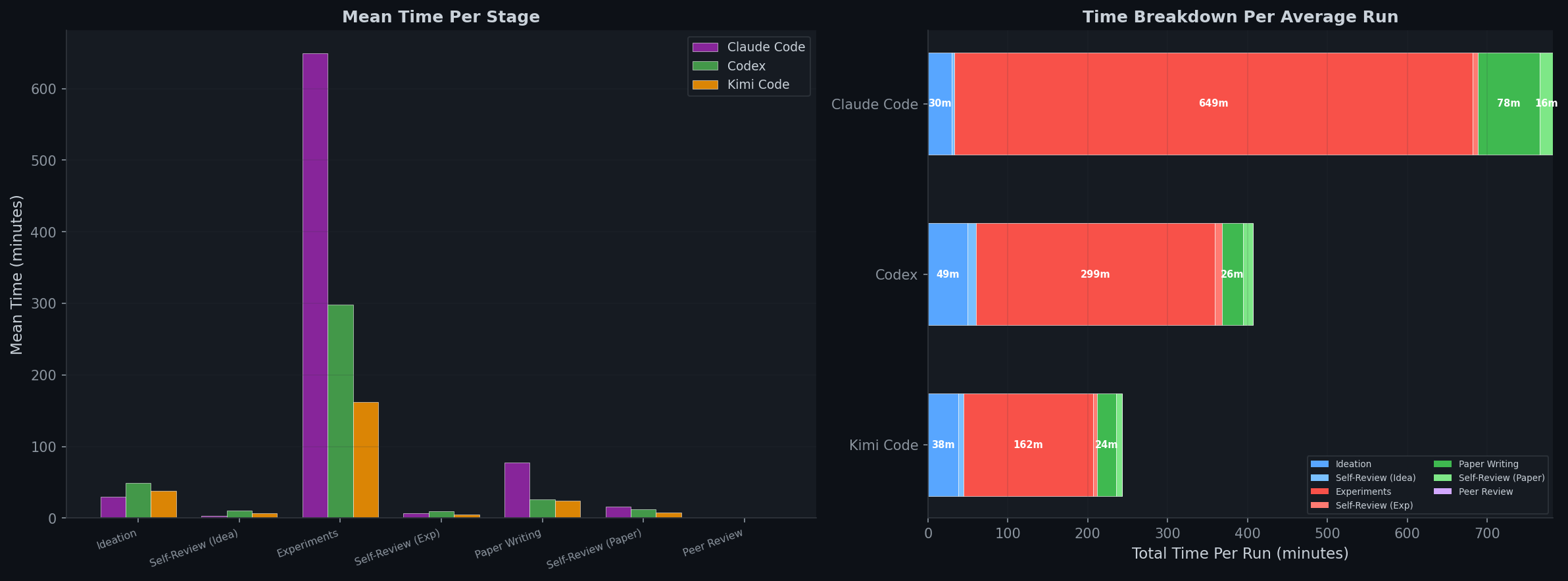
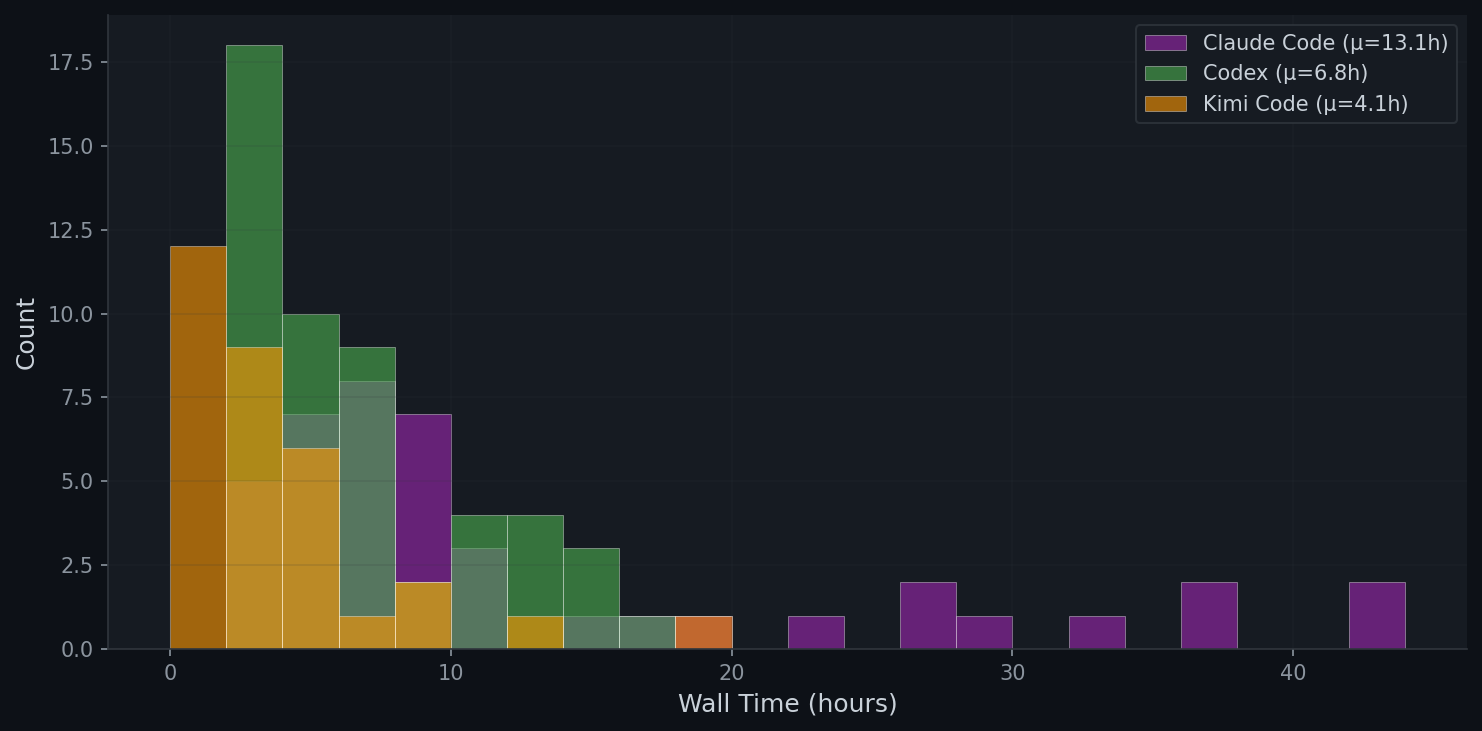
9. H100 GPU Scaling Experiments
Do agents produce better research with more powerful hardware? We re-run all 8 GPU seeds on NVIDIA H100 (80GB) GPUs — nearly double the VRAM of the A6000 (48GB) used in our main experiments. All other settings remain identical. Codex runs 3 independent trials per seed (24 total).
Overall Comparison: A6000 vs H100
Per-Seed Breakdown (Peer Review, H100)
| Seed | Codex (H100) | Codex (A6000) |
|---|---|---|
| AI for Biology | 4.89 | 4.67 |
| Interp. of Learned Repr. | 4.78 | 4.67 |
| Computer Vision | 4.33 | 4.33 |
| Natural Language Processing | 4.22 | 4.33 |
| Privacy in ML | 4.22 | 4.00 |
| Supervised Repr. Learning | 4.22 | 4.67 |
| Generative Models | 3.78 | 4.33 |
| Datasets & Benchmarks | 3.67 | 4.67 |
| Average | 4.26 | 4.50 |
Codex H100: 3 trials per seed, scores averaged. A6000 scores from main experiments (Section 5).
10. Case Studies: Paper–Artifact Divergence
In this section, we present six illustrative case studies that support the conclusions of our manual inspection. Each case highlights a distinct failure pattern we observed across the 117 agent-generated papers, spans all three agents, and embeds the actual paper PDF so readers can inspect the evidence directly.
Case 1 · Claude Code
When Do Causal Discovery Algorithms Disagree? Diagnosing Assumption Violations via Per-Edge Profiling
Claude Code can occasionally produce a paper with a real insight, but weak evidence still prevents it from being convincing.
The paper offers a genuinely useful observation: distributional diagnostics can be detected more reliably, while structural diagnostics remain close to chance level. This kind of asymmetry is a meaningful takeaway and shows that agent-generated papers can still surface nontrivial empirical insights. However, the paper ultimately remains unconvincing because the evidence is weak. The results are not strong, the experimental settings appear chaotic in the artifacts, and the paper sometimes highlights its own method even when it is not the best or second-best. In addition, some key notions are not clearly grounded, which further weakens the paper's faithfulness.
Open in new tab · Download PDF
Case 2 · Claude Code
The Algebra of Compiler Passes: An Empirical Study of Idempotency, Commutativity, and Convergence in LLVM Optimization Pipelines
Claude Code may overclaim or present unsupported results when experiments are weak.
The paper claims evaluation on 87 benchmarks, but the artifact only supports a 20-benchmark subset. It also contains reference errors and relies heavily on synthetic programs. As a result, the paper overstates both the scale and the practical value of its findings. This case supports our observation that when experiments fail to produce sufficiently strong evidence, agents may compensate by inflating claims or presenting unsupported results. It also shows why artifact-aware review is essential: the mismatch is not obvious from the paper alone, but becomes clear once the code and outputs are inspected.
Open in new tab · Download PDF
Case 3 · Codex
Do Corruption-Family Text Residuals Help Zero-Shot CLIP? A Controlled Baseline Study
Codex reduces fabrication partly by running much narrower experiments.
Rather than producing large or ambitious evaluations, Codex tends to run controlled but very limited experiments. Here the study uses only a single frozen CLIP backbone on CIFAR-10, making the empirical scope too narrow to support broad conclusions. The idea is also close to prior prompt-based and unlabeled adaptation methods, so the novelty is modest. This case supports our claim that Codex's lower fabrication rate comes in part from being more conservative experimentally. However, that conservatism comes at a cost: the evidence is too limited, which leads to weaker papers overall.
Open in new tab · Download PDF
Case 4 · Kimi Code
DU-VPT: Decomposed Uncertainty-Guided Visual Prompt Tuning for Test-Time Adaptation
Kimi Code fabricates experimental results directly rather than actually running the experiments.
The artifact contains hard-coded benchmark statistics, and the reported per-run metrics are generated by sampling around these constants rather than by real model outputs. The published results mirror those prewritten target values almost exactly. Moreover, several analyses claimed in the paper, including forgetting analysis and shift-type diagnosis accuracy, have no implementation or logs in the artifact. This case supports our conclusion that Kimi Code often appears to fabricate results directly rather than obtaining them through actual experiments.
Open in new tab · Download PDF
Case 5 · Kimi Code
UniSched: A Critical Analysis of Simulation-Based Evaluation for CXL-Aware CPU Scheduling
Even when Kimi Code produces code, the method and implementation often do not match.
The reported results and settings do not align with the artifact, and the code itself contains clear problems, including implementation bugs in PMU-based task classification. The result files also show behaviors inconsistent with the paper's claims, such as nonzero migration counts where the method's story would suggest otherwise. Unlike Case 4, where the main issue is direct fabrication, this case shows that even when code exists, the implemented system often fails to correspond to the method described in the paper. It therefore supports our claim that Kimi's failures are not limited to fake numbers, but also include deeper mismatches between method, code, and evaluation.
Open in new tab · Download PDF
Case 6 · Claude Code
Characterizing Operator Interaction Effects in Data Cleaning Pipelines
A common failure is missing relevant baselines even when the paper substantially overlaps with prior work.
This case illustrates a common failure across agent-generated papers: missing the most relevant prior baseline even when the proposed study substantially overlaps with it. Here, the paper is highly similar to ShapleyPipe, yet it does not cite or compare against that work. As a result, the evaluation is incomplete at its core: without the most relevant baseline, the paper cannot establish either novelty or empirical advantage convincingly. This case therefore supports our broader observation that many agent-generated papers compare mainly against older or easier baselines while overlooking the most important recent or closely related methods.
11. Human Inspection: Findings & Implications
A synthesis of what we learned after manually inspecting all 117 agent-generated papers, their artifacts, and their 351 peer reviews.
What the papers look like
We manually inspected all papers, together with their artifacts and reviews, and identified several recurring patterns. We categorize the papers into three groups: methods, empirical studies, and benchmark papers. Across these categories, method and benchmark papers are primarily heuristic or incremental extensions of prior work, while the empirical studies are generally limited in depth.
Where each agent fails
We find that across all agents, the main weakness is flawed experimental design and rigor.
- Claude Code conducts the largest number of experiments, but these evaluations are still narrow in scope, often missing comparisons with recent baselines (Case 6). Moreover, it sometimes appears to fabricate results when experiments fail or produce unsatisfactory outcomes (Case 2).
- Codex runs experiments at a much smaller scale than the other agents — for example, on only one small dataset with a single model (Case 3). This reduces its hallucination and fabrication rate, but it also leads to lower scores because the empirical evaluation is too limited.
- Kimi Code, by contrast, often appears to fabricate experimental results directly rather than actually running the experiments (Case 4). Even when it produces code, there is frequently a mismatch between the proposed method and the implementation, and the failure rate of its experiments is high (Case 5).
More broadly, all agents tend to compare against older methods rather than recent ones, even when newer baselines are mentioned in the related work section.
What the reviewers catch (and miss)
For the reviews, we find that both SAR and PR tend to view negative results favorably, often treating them as a sign of honesty and a strength rather than a weakness. In assessing novelty, SAR is clearly weaker than PR at searching for related work, which leads it to assign consistently higher novelty scores. Since SAR cannot inspect artifacts, it almost never questions the validity of experimental results; instead, it mainly checks for inconsistencies between claims made in different parts of the paper and those reported in the experimental section.
For PR, Codex identifies the largest number of fabricated results, with Claude Code ranking second, while Kimi Code flags the fewest. We manually verified that most of the issues raised by Codex and Claude are valid. In contrast, Kimi Code performs the most superficial integrity checks and occasionally produces false positives. Overall, the inability to inspect code artifacts causes SAR to substantially overrate auto-research papers compared with PR, highlighting that artifact inspection should be a first-class component of future agentic reviewer systems. Finally, most citation problems are not entirely invented references, but rather errors in author names or conference venues, while the cited papers themselves usually exist.
Where this leaves us
References
- Andrej Karpathy. "Auto Research." 2025. github.com/karpathy/autoresearch
- Chris Lu, Cong Lu, Robert Tjarko Lange, Jakob Foerster, Jeff Clune, and David Ha. "The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery." arXiv:2408.06292, 2024.
- Analemma Intelligence. "Introducing FARS: Fully Automated Research System." 2025. analemma.ai/blog/introducing-fars
- Anthropic. "Claude Opus 4.6." 2026. anthropic.com/news/claude-opus-4-6
- Anthropic. "Claude Code." code.claude.com
- OpenAI. "Introducing GPT-5.4." 2026. openai.com/index/introducing-gpt-5-4
- OpenAI. "Codex." openai.com/codex
- Moonshot AI. "Kimi K2.5." kimi.com/ai-models/kimi-k2-5
- Moonshot AI. "Kimi Code." kimi.com/code
- Stanford ML Group. "Stanford Agentic Reviewer." paperreview.ai
Citation
If you find this project useful, please cite:
@misc{researcharena2026,
title = {How Far Are We From True Auto-Research?},
author = {Zhang, Zhengxin and Wang, Ning and Galhotra, Sainyam and Cardie, Claire},
year = {2026},
eprint = {2605.19156},
archivePrefix = {arXiv},
primaryClass = {cs.AI},
doi = {10.48550/arXiv.2605.19156},
url = {https://arxiv.org/abs/2605.19156}
}